
El nuevo modelo de aprendizaje desarrollado por Hewlett Packard Labs, la organización de I+D de HPE, es el el primer marco de aprendizaje automático descentralizado que preserva la privacidad de la industria para el borde o sitios distribuidos y se trata de una solución que proporciona a los clientes contenedores que se integran fácilmente con IA, de manera que los usuarios pueden compartir de inmediato los aprendizajes del modelo de IA dentro de su organización y fuera con colegas de la industria para mejorar la capacitación, sin llegar a compartir datos reales.“El aprendizaje de enjambre es un enfoque nuevo y poderoso para la IA que ya ha progresado en abordar desafíos globales como el avance de la atención médica del paciente y la mejora de la detección de anomalías que ayudan esfuerzos en detección de fraude y mantenimiento predictivo”, señalaba Justin Hotard, vicepresidente ejecutivo de HPE. “HPE está contribuyendo al movimiento de aprendizaje en enjambre de manera significativa mediante la entrega de una solución de clase empresarial que permite a las organizaciones colaborar, innovar y acelerar el poder de los modelos de IA, preservando al mismo tiempo el valor ético de cada organización así como la privacidad de los datos y los estándares de gobierno”.
Un nuevo enfoque de IA que permite compartir los conocimientos de forma segura
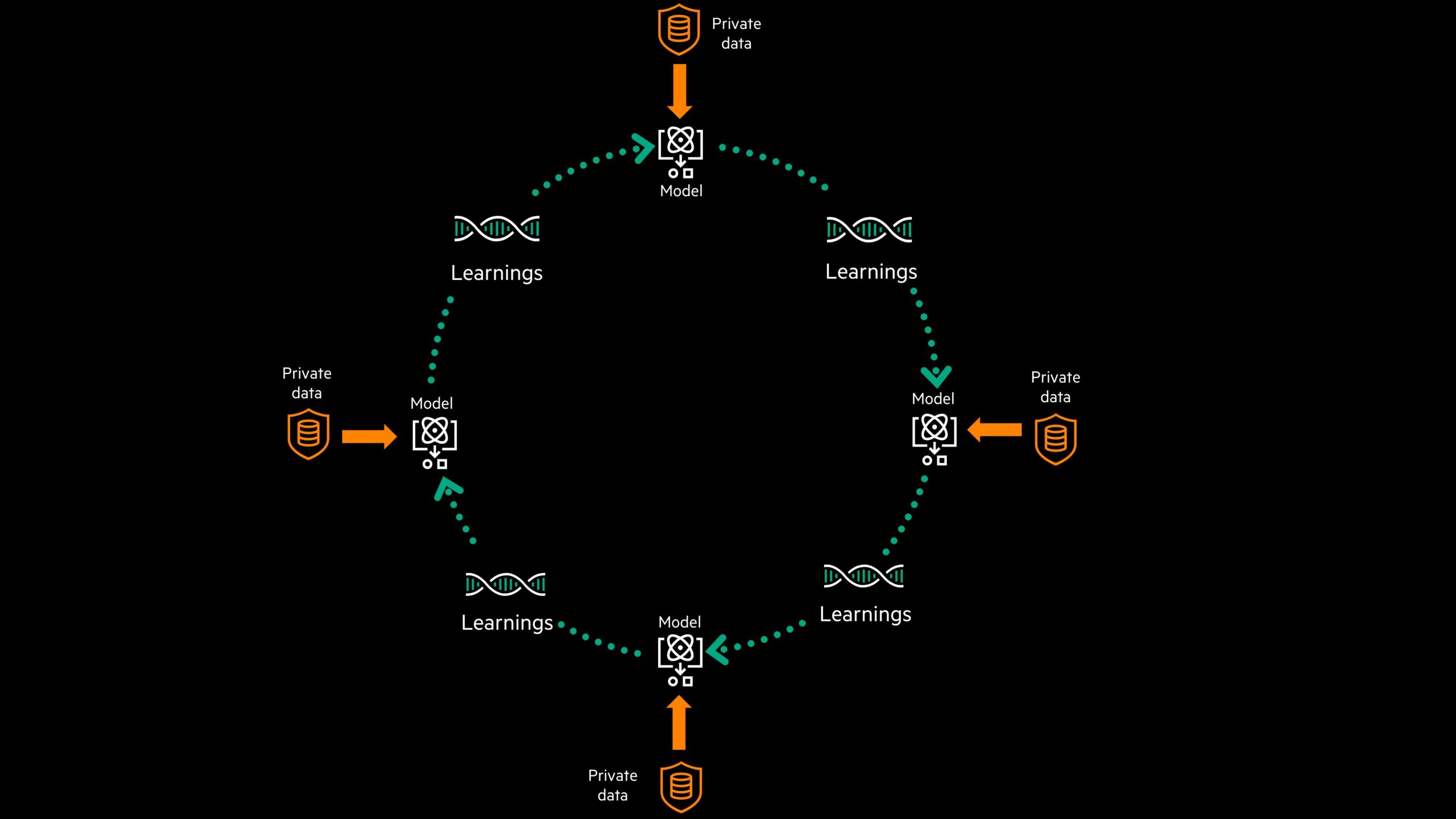
Hoy en día, la mayor parte del entrenamiento del modelo de IA ocurre en una ubicación central, que se basa en conjuntos de datos combinados. Sin embargo, este enfoque puede ser ineficiente y costoso debido a que tiene que mover grandes volúmenes de datos de vuelta a la misma fuente y también puede estar limitado por la privacidad de los datos y la reglas y regulaciones de propiedad que limitan su intercambio y que pueden producir modelos inexactos y sesgados.
Por tanto, el objetivo de esta nueva tecnología es entrenar modelos y aprovechar los conocimientos en el perímetro para que las empresas puedan tomar decisiones más rápido, en el punto de impacto, lo que lleva a mejores experiencias y resultados. Además, se pueden compartir los aprendizajes de una organización con otra en la fuente de datos y las industrias de todo el mundo pueden unirse y mejorar aún más la inteligencia, dando lugar a resultados empresariales y sociales.
“Creemos que es muy interesante para empresas globales y la industria de la comunicación, para los que también es una oportunidad significante de colaborar y mejorar los conocimientos”
Sin embargo, compartir datos externamente puede plantear un desafío para las organizaciones que deben cumplir requisitos de gobierno de datos, reglamentarios o de cumplimiento, que exigen que los datos permanezcan en su ubicación. HPE Swarm Learning permite de manera única a las organizaciones utilizar datos distribuidos en su origen, lo que aumenta el tamaño del conjunto de datos para el entrenamiento y para construir modelos de aprendizaje automático para aprender de manera equitativa mientras se preserva el gobierno de datos y la privacidad.
Para garantizar que solo se comparten los aprendizajes capturados de la edge y no los datos en sí, HPE Swarm Learning utiliza tecnología de cadena de bloques para incorporar miembros, elegir dinámicamente un líder y fusionar parámetros del modelo para proporcionar resiliencia y seguridad a la red de enjambre y el hechod e que se se compartan solamente los aprendizajes, HPE Swarm Learning hace que no se comprometa la privacidad y ayuda a eliminar sesgos para aumentar la precisión en los modelos.
Además, HPE también ha anunciado que está trabajando en la eliminación de las barreras para que las empresas construyan y entrenen fácilmente modelos de Machine Learning a escala, para generar valor más rápido, con el nuevo HPE Machine Learning Development System. El nuevo sistema, diseñado específicamente para IA, es una solución integral que engloba una plataforma de software de machine learning, computación, aceleradores y comunicaciones para desarrollar y entrenar modelos de IA más precisos, más rápidos y a escala.
Potenciar la IA para el bien común
Una tecnología que tendrá aplicaciones en muchas y distintas áreas:
- Los hospitales pueden obtener aprendizajes a partir de registros de imágenes, tomografías computarizadas y resonancias magnéticas y expresión genética. Son datos que se compartirán de un hospital a otro para mejorar el diagnóstico de enfermedades y otras dolencias, al tiempo que protege la información del paciente.
- Los servicios bancarios y financieros pueden combatir la pérdida global esperada de más de $400 mil millones en fraude con tarjetas de crédito durante la próxima década, al compartir aprendizajes relacionados con el fraude con más una institución financiera a la vez.
- Los sitios de fabricación pueden beneficiarse del mantenimiento predictivo para obtener información sobre los equipos necesidades de reparación y abordarlas antes de que fallen y provoquen tiempos de inactividad no deseados. Aprovechando el aprendizaje de enjambres, los gerentes de mantenimiento pueden obtener una mejor perspectiva al recopilar aprendizajes a partir de datos de sensores en múltiples sitios de fabricación.
Un ejemplo real donde ya se ha utilizdo esta tecnología es la Universidad de Aquisgrán,que estudia la histopatología para acelerar el diagnóstico del cáncer de colon. Allí, un equipo de investigadores realizó un estudio para avanzar en el diagnóstico de cde este tipo de cáncer aplicando la IA en el procesamiento de imágenes para predecir alteraciones genéticas que provocan que las células se vuelvan cancerosas.
Los investigadores entrenaron modelos de IA utilizando HPE Swarm Learning y los resultados demostraron que los modelos originales de IA, que entrenaban solo en datos locales, se superaron utilizando este tipo de aprendizaje “en enjambre” compartiendo el modelo de aprendizaje pero no los datos del paciente, llegando a mejorar otro tipo de entidades de IA que se utilizan para hacer predicciones.

